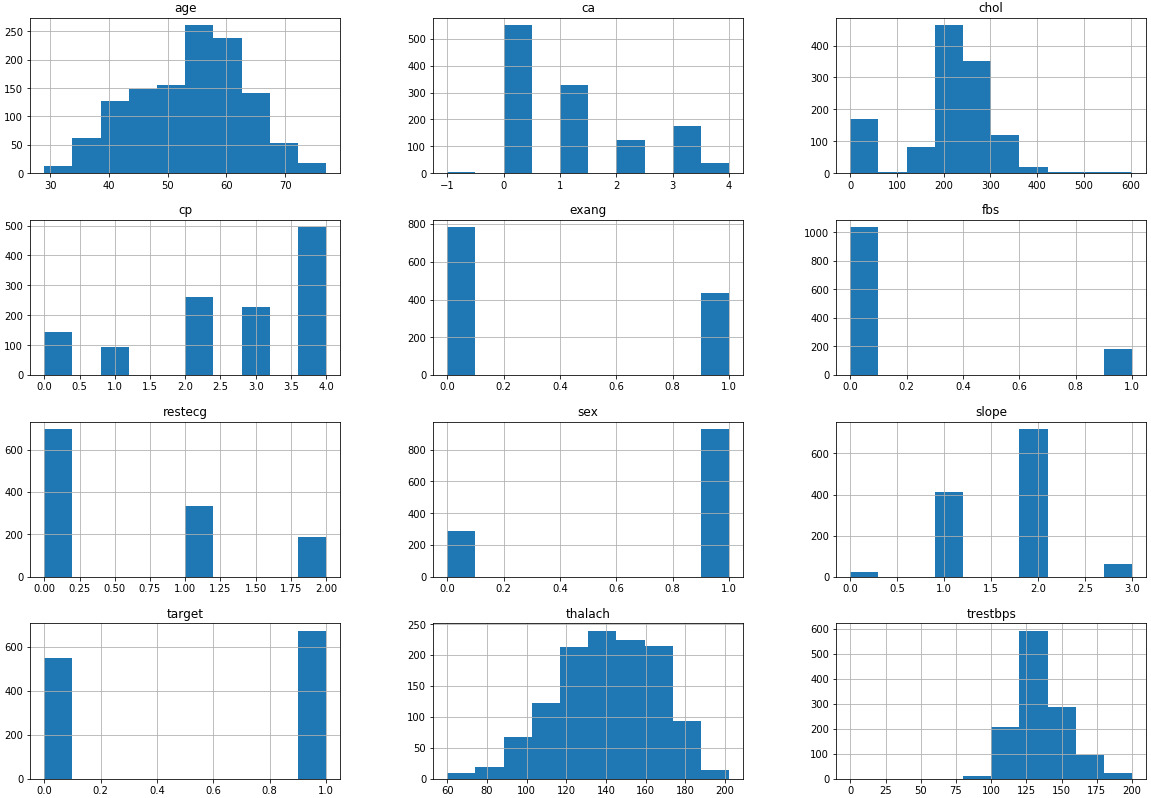
Der Datensatz
Für das „machine learning“ Programm werden bestimmte „Risikoparameter für eine Herzinsuffizienz“ ermittelt:
• Alter
• Geschlecht
• Brustschmerz Art
• Blutdruck im Ruhezustand
• Cholesterin-Spiegel
• Puls unter Belastung
• Luftnot oder Angina Pectoris
• Blutzucker vor dem Essen
• ST-Segment Veränderungen
Übersicht über alle Parameter, die wir in unserem Trainingsprozess nutzen:
Was macht einen guten Datensatz aus?
• Größe
• Anzahl der fehlenden Werte
• Geringe Ausreißer
• Passende Features
• Ausgewogenheit zwischen den Labels
• Verlässlichkeit (sind richtige Labels gesetzt?)
→ Überprüfung über Visualisierung und
• genaue Analyse der Daten
Eine KI ist nur so gut, wie die Daten aus denen sie lernt.
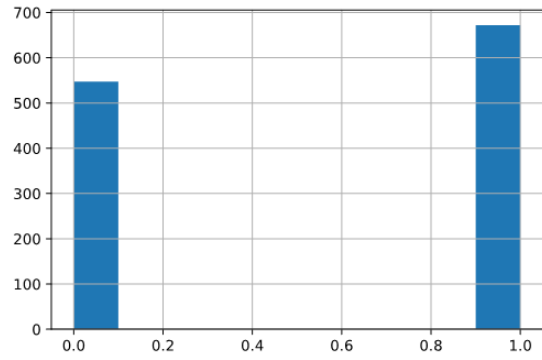
Gleichmäßige Verteilung der Labels:
Was haben wir gemacht?
Datensatz mit 1220 Patientendaten gefunden
Missing values ergänzt durch „machine learning“
Daten richtig formatiert (z.B erstellen von Dummy-Spalten)
Daten analysiert um Auffälligkeiten zu entdecken
Fachgespräch mit Kardiologen um die Parameter zu beurteilen
Möglichkeit mit missing values umzugehen:
• Entfernen des gesamten Patientendatenpunktes
• Einfachste Lösung, Verlust von Datenpunkten, keine Schätzung von Werten, die zu einer schlechten Accuracy führen könnten
• Füllen der Lücke mit Mean- oder Medianwert
• Leicht zu realisieren, kein Verlust von Daten, ungenau
• Vorhersagen der Lücke mit Hilfe von „machine learning“
• Zeitaufwand, genauere Vorhersage, kein Verlust von Daten
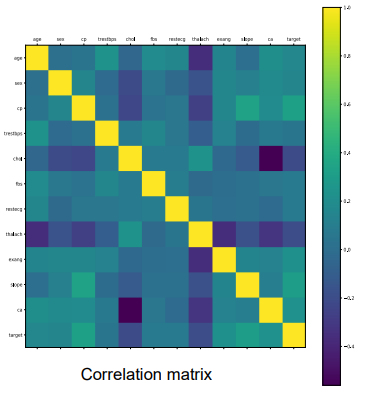
Correlation Matrix
| Startseite | Was ist eine Herzinsuffizienz? | Das “machine learning” Modell | Accuracy | Das Team |
| Datenschutz | Impressum |